
Video-Specific Autoencoders for
Exploring, Editing and Transmitting Videos.
|
|
|
|
|
|
|
|
|
We study video-specific autoencoders that allow a human user to explore, edit, and efficiently transmit videos. Prior work has independently looked at these problems (and sub-problems) and proposed different formulations. In this work, we train a simple autoencoder (from scratch) on multiple frames of a specific video. We observe: (1) latent codes learned by a video-specific autoencoder capture spatial and temporal properties of that video; and (2) autoencoders can project out-of-sample inputs onto the video-specific manifold. These two properties allow us to explore, edit, and efficiently transmit a video using one learned representation. For e.g., linear operations on latent codes allow users to visualize the contents of a video. Associating latent codes of a video and manifold projection enables users to make desired edits. Interpolating latent codes and manifold projection allows the transmission of sparse low-res frames over a network. |
|
K. Wang, D. Ramanan, and A. Bansal Video-Specific Autoencoders for Exploring, Editing and Transmitting Videos. |
| We visualize the latent code learned by a video-specific autoencoder via multidimensional scaling with PCA. We find that video-specific autoencoders learn a temporally continuous representation without any explicit temporal information. We show this property for various natural videos. This continuous latent representation allows one to slow-down or speed-up a video (through latent code resampling) and enables interactive video exploration. |
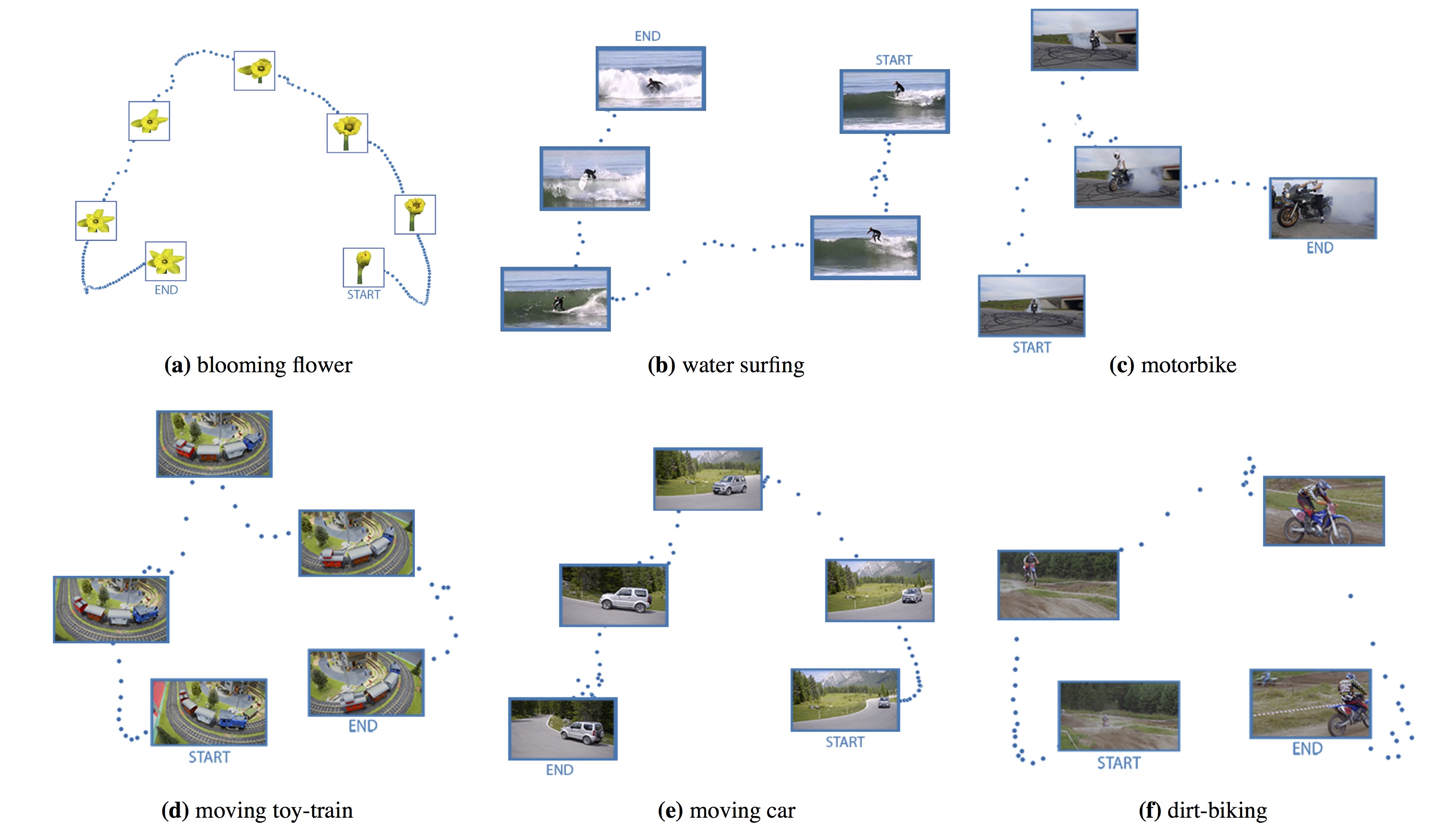  |
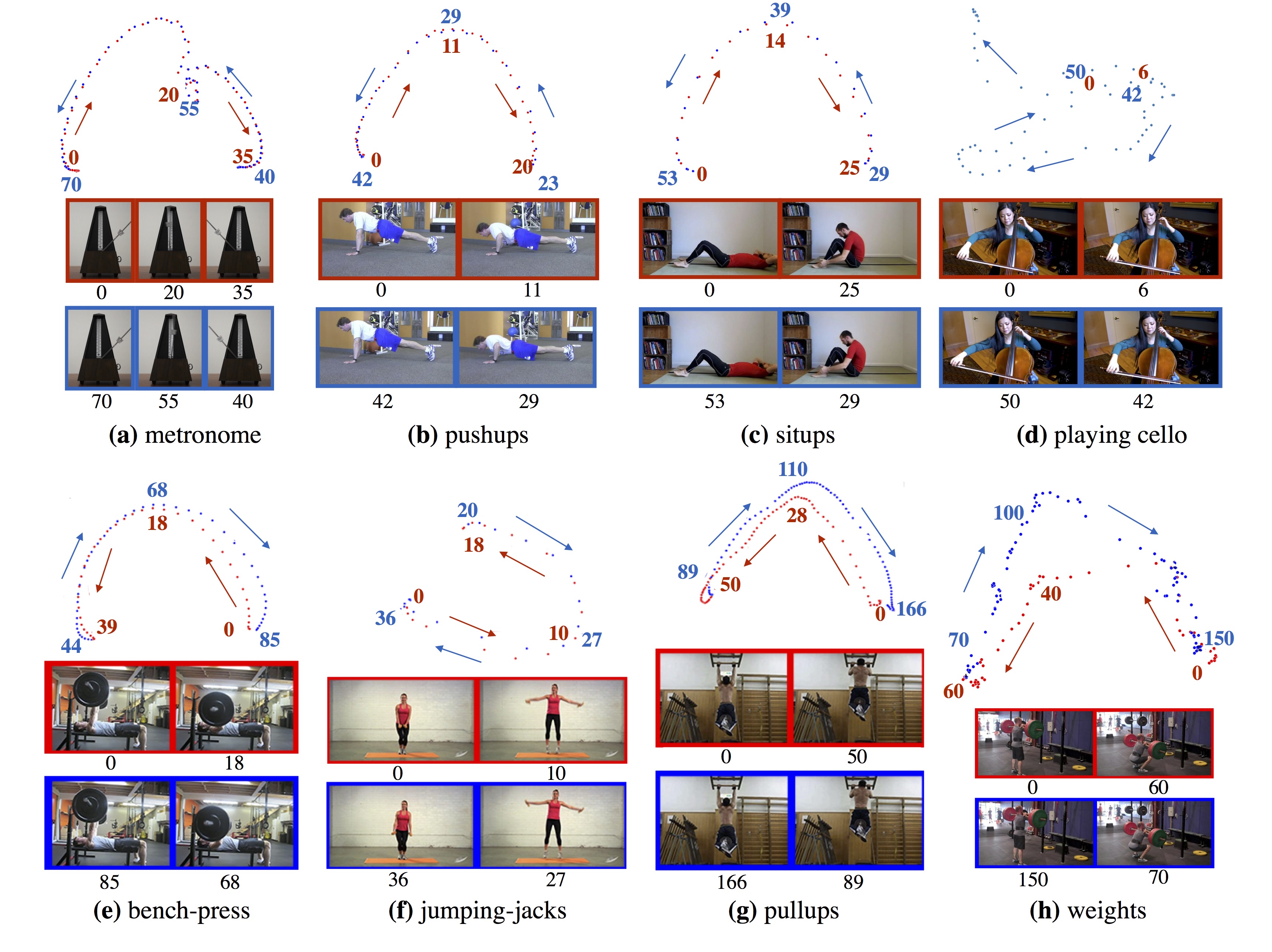
| We observe that latent spaces are able to learn the repetitive motion without using any temporal information. We show examples of (a) metronome, (b) pushups, (c) situps, (d) playing cello, (e) bench-press, (f) jumping-jacks, (g) pullups, and (h) carrying weights. Latent spaces are also tuned to capture video-specific subtleties. In the example of playing cello (d), we observe that the "stretched-out" hand posture in down-bow and up-bow are nearby in latent space even though far apart temporally. |
 |
|
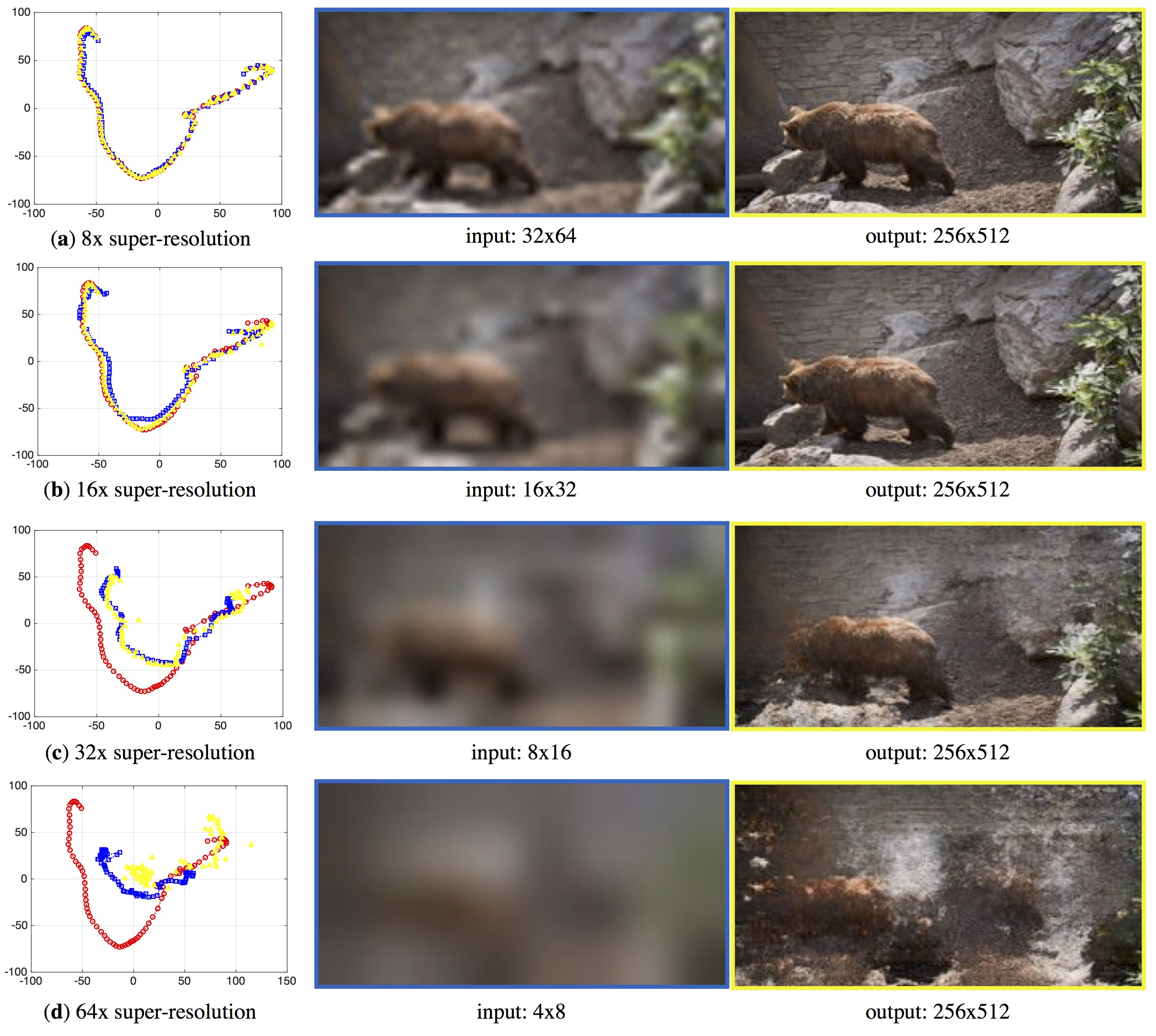
We train a video instance specific autoencoder using 82 individual frames of 256x512 resolution from a bear sequence. We visualize the latent codes for the original frames using the RED points on the left side. At test time, we input low-res frames of varying resolution. We visualize the latent codes for the low-res input using the BLUE points. We also visualize the latent codes for the output image using the YELLOW points. We observe that RED points, BLUE points, and YELLOW points for (a) 8X super-resolution and (b) 16X super-resolution overlaps. We also observe perfect reconstruction for these two cases. The results, however, degrade as we further reduce the resolution of images. This is shown using examples for (c) 32X super-resolution and (d) 64X super-resolution. |
 |
|
We input a low-res 8x16 image and iteratively improve the quality of outputs. The reprojection property allows us to move towards a good solution with every iteration. At the end of the fifth iteration, we get a sharp hi-res (256x512) output despite beginning with an extremely low-res input. |
 |
|
We input a low-res 4x8 image and iteratively improve the quality of outputs. The reprojection property allows us to move towards a good solution with every iteration. At the end of the tenth iteration, we observe a sharp but plausible hi-res (256x512) output. However, it may not be an actual solution. |
 |
|
A simple reconstruction of the average of latent codes in a video also allows us to see the average summary of a video. We compute an average image by taking an average of the latent codes of individual frames (along with iterative reprojection property of autoencoder). We contrast it with the per-pixel average of frames and observe sharp results. |
     |
| We embed (a) an eleven-minute video of Mr Bean with a video-specific autoencoder and (b) a five minutes video on wolves. Our approach allows us to quickly visualize the contents of the video by providing an average summary of the selected region. A user can select the region on the 2D visualization. Our approach generates the centroid of the points in selected region. We also show mediod corresponding to each centroid. A user can quickly glance by browsing over the points or selecting the region. |
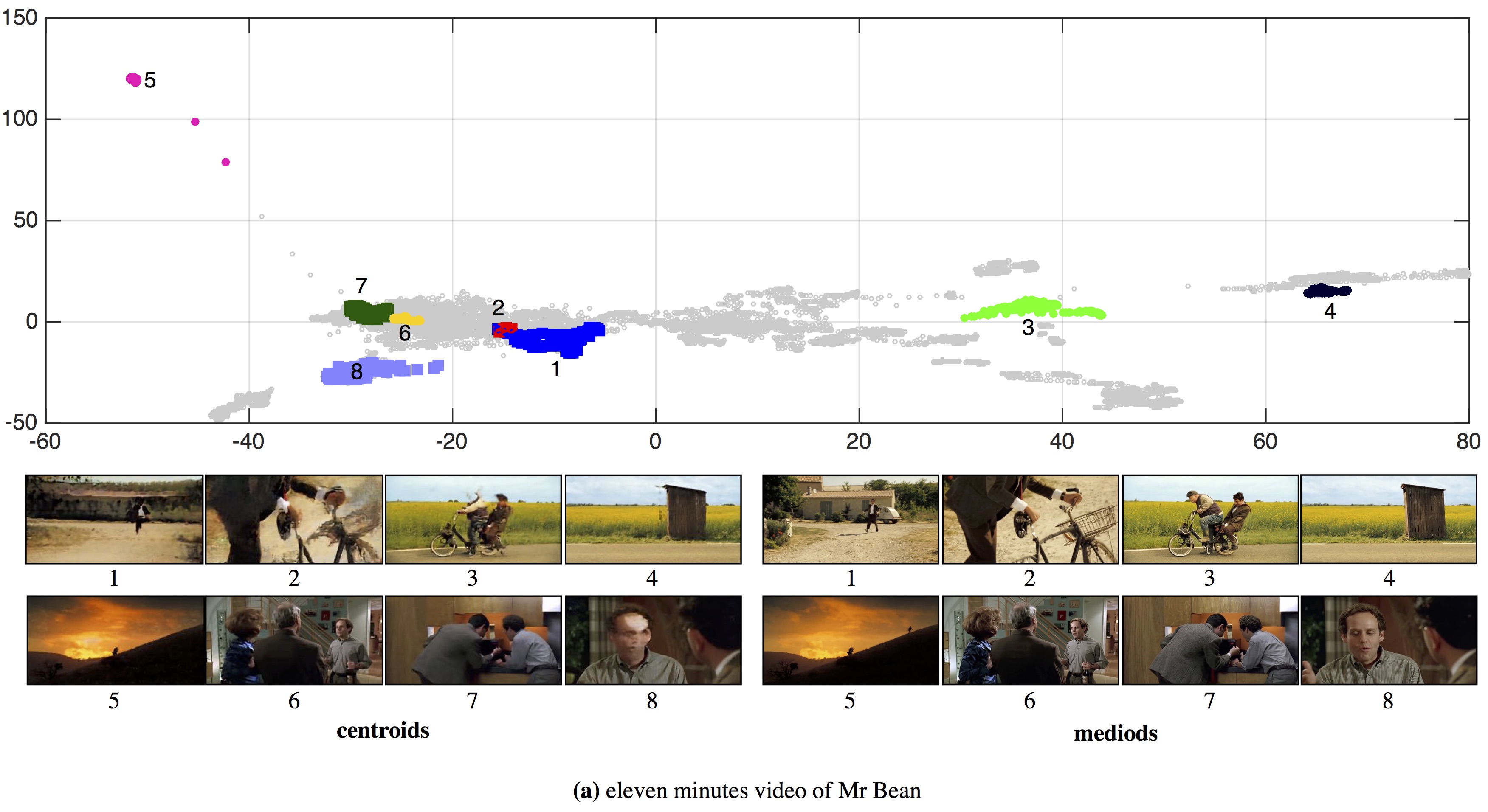 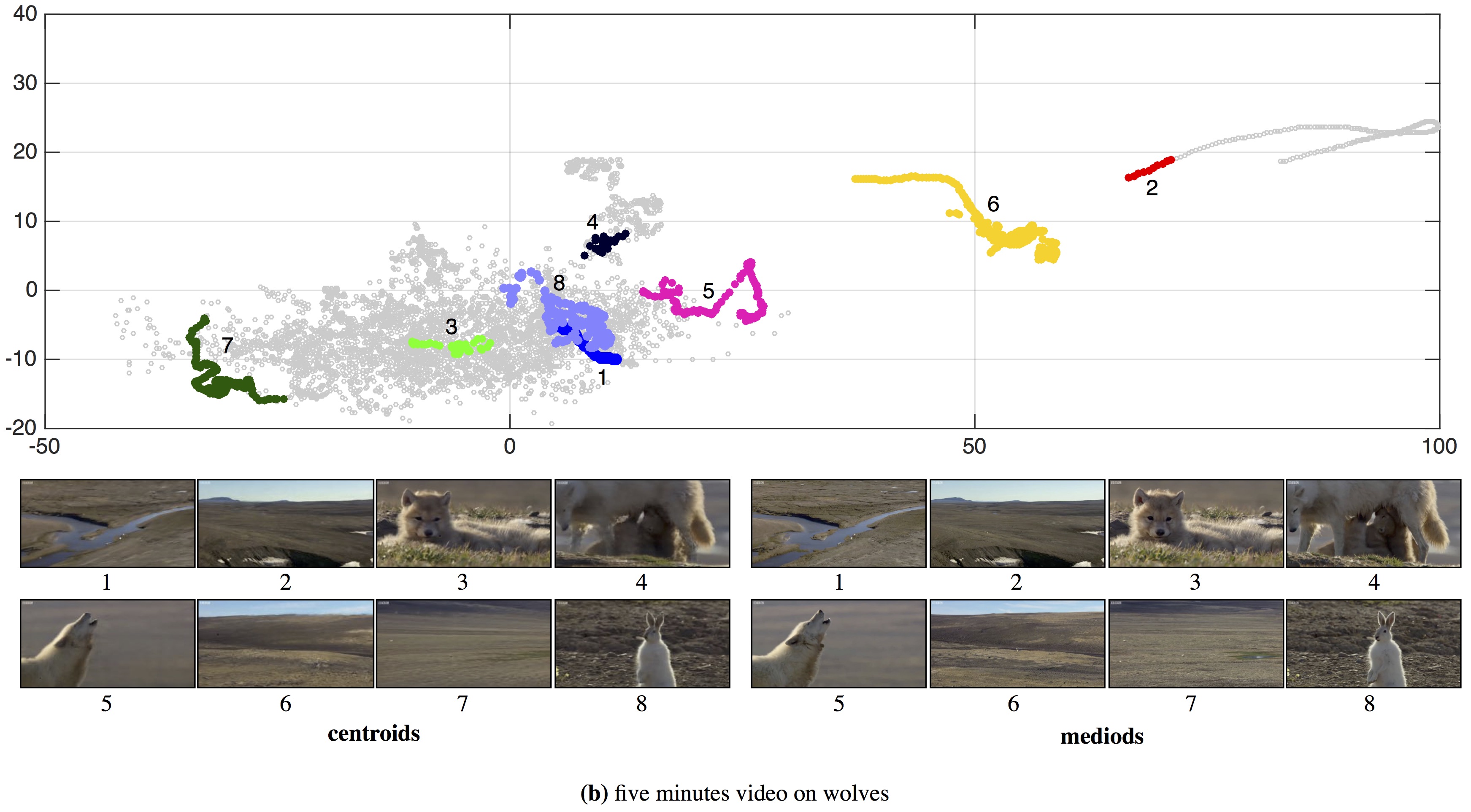 |
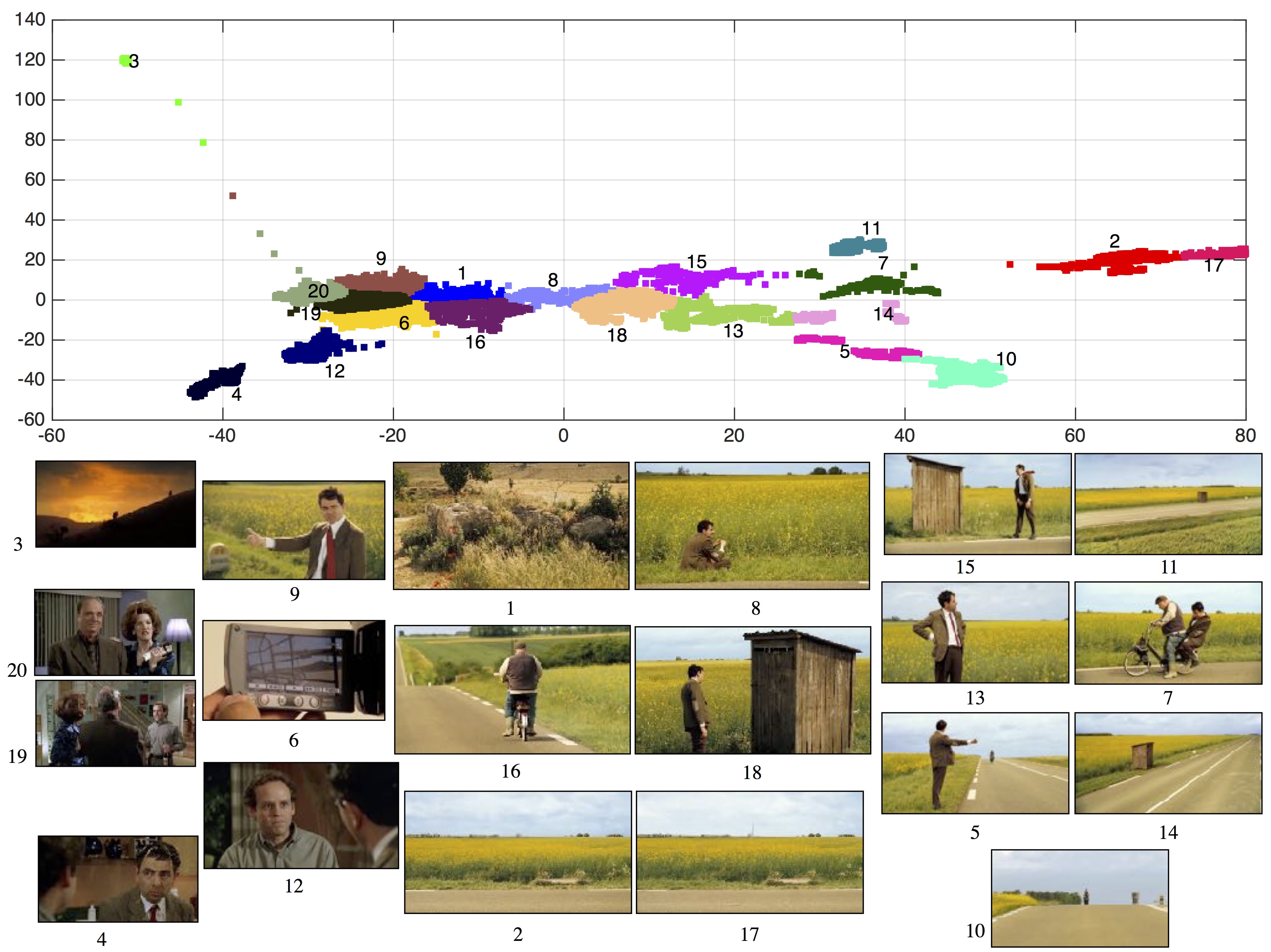
| Quickly Glancing a Video: We partition 15,679 frames from Mr Bean's video in 20 clusters. We show mediods for each cluster as the representative frame. This allows a user to quickly glance the contents of a video. We can further use the temporal ordering in the video to create a video strip that sequentially summarizes the entire video. |
 |
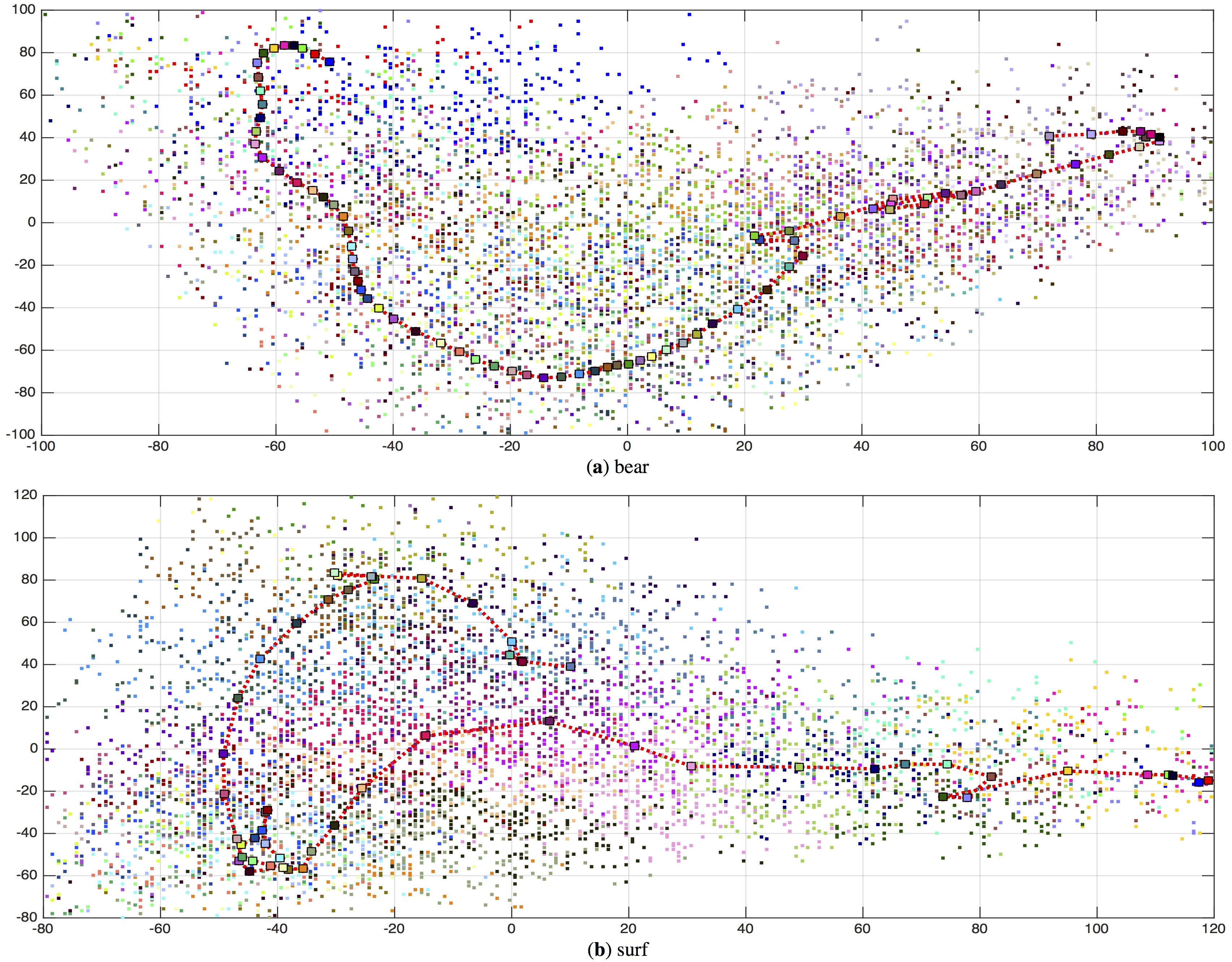
| We train a video instance specific autoencoders on (a) 82 individual frames from a bear sequence, and (b) 55 individual frames from a surfing sequence. We visualize the latent codes of original points on a 2D plot for this sequence using the bold squares. Each square represents an original frame in the video and is shown using a different color. The red line connecting the squares show the temporal sequence. We show random points on manifold M colored by the closest original frame. We observe that latent coordinates even far away from the original frames tend to produce high-quality image reconstructions. |
 |
|
The reprojection property of autoencoder enables us to learn patch-level statistics in a frame. We show examples of removing unwanted distractions (marked with red box on left side), or user edits on frames. The autoencoder generates a continuous spatial image. |
   |
| We naively concatenate the spread-out frames in a video and feed it through the video-specific autoencoder. The learned model generates a seamless output. |
  |
| Given a 256x512 frame of a video (shown in the red box on the left), we stretch it horizontally to 256x2048 and feed it to a learned video-specific autoencoder. We iterate 30 times and get a consistent panorama-type output. |
  |
|
Given a image, a user can do editing by copy-pasting a patch from surroundings to the target location and feed it to the video-specific autoencoder. We show examples (input-output pairs) of spatial editing for stretched out images. The video-specific autoencoder yields a continuous and consistent spatial outputs as shown in the various examples here. |
  |
| Insertion: We show more examples (input-output pairs) of spatial editing for stretched out images. Here a user inserts patches from far-apart frames and feed it to the video-specific autoencoder. The autoencoder generates a continuous spatial output. However, there are no guarantees if the video-specific autoencoder will preserve the input edits. It may generate a completely different output at that location. For e.g., we placed small fishes in the bottom example but the video-specific autoencoder chose to generate different outputs. |
 |
10x Spatial Super-Resolution via reprojection property |
| Given a 256x512 image, we spatially extrapolate on its edges to create a 512x1024 image. To do this, we mirror-pad the image to the target size and feed it to the video-specific autoencoder. We also show the results of zero-padding here. While mirror-padded input preserves the spatial structure of the central part, zero-padded input leads to a different spatial structure. |
  |
  |
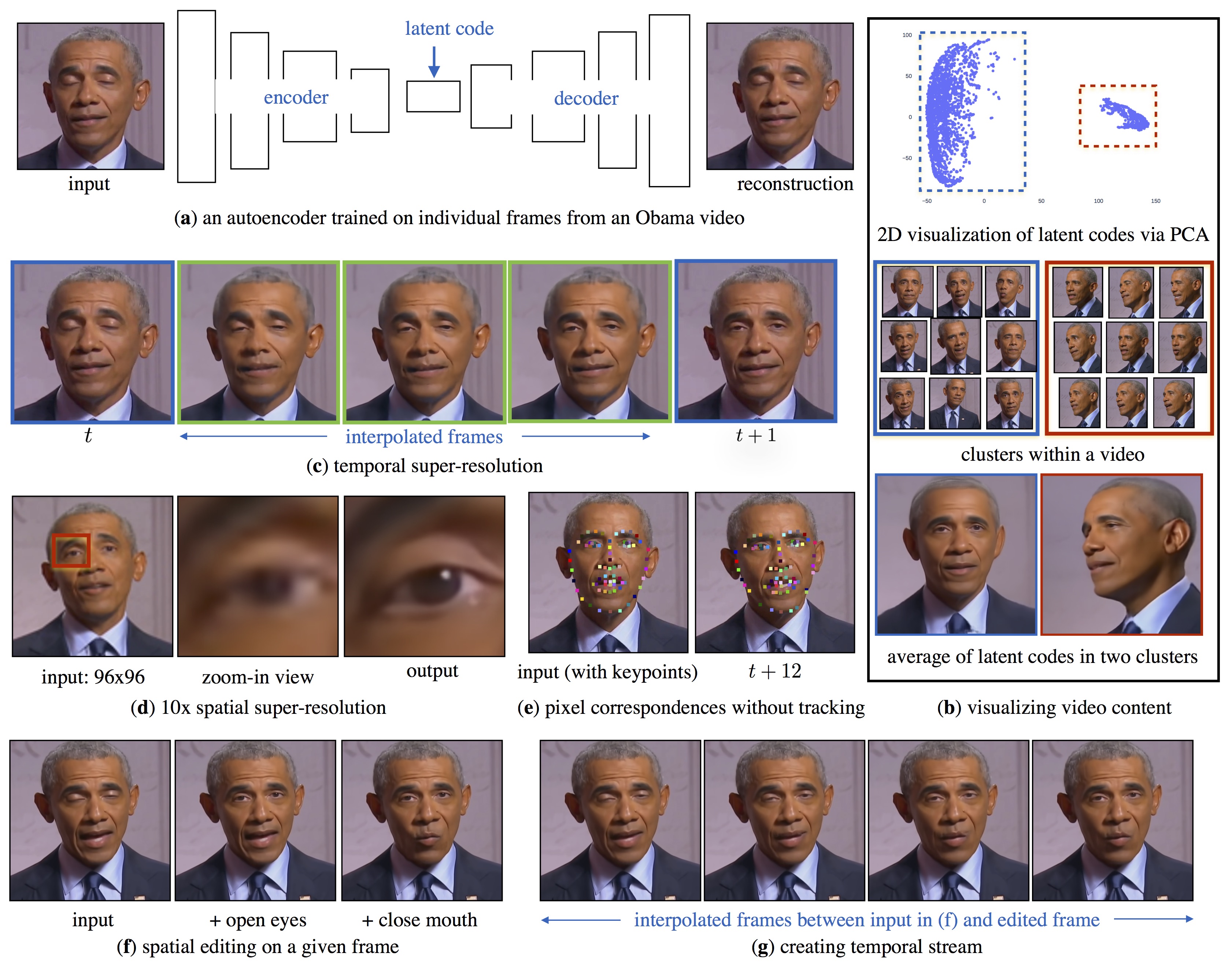 |
| What can we do with a video-specific representation?: (a) We train a video-specific autoencoder on individual frames from a target video (here, 300 unordered 1024x1024 frames). (b) We use Principal Component Analysis (PCA) to visualize latent codes of the frames of this video in a 2D space. This 2D visualization shows two different data distributions within the video. We visualize the clusters within the video and average of latent codes in these two clusters. (c) We interpolate the latent codes of adjacent frames (and decode them) for temporal super-resolution. (d) By linearly upsampling low-res 96x96 image frames to 1024x1024 blurry inputs and passing them through the autoencoder, we can "project" such noisy inputs into the high-res-video-specific manifold, resulting in high quality 10X super-resolution, even on subsequent video frames not used for training. (e) We use multi-scale features from the encoder and can do pixel-level correspondences between two frames in a video. (f) We can also do spatial editing on a given frame of video. Shown here is an input frame where eyes are closed. We copy open eyes from another frame and close mouth from a yet another frame, and pass it through the autoencoder to get a consistent output. (g) We can further create temporal stream between the original frame and edited frame by interpolating the latent code. |
 |
| Video-Specific Autoencoders: We demonstrate a remarkable number of video processing tasks enabled by an exceedingly simple video-specific representation: an image autoencoder trained on frames from a target video. (a) By interpolating latent codes of adjacent frames (and decoding them), one can perform temporal super-resolution. (b) The reprojection property of autoencoder allows us to input blurry low-res 96x96 image frames and get sharp hi-res 1024x1024 outputs, resulting in high quality 10X super-resolution, even on subsequent video frames not used for training. (c) The video-specific manifold learned by autoencoder allows us to remove objects in a video with a simple bounding box. (d) The multi-scale features of an autoencoder can be used to establish per-pixel correspondences across frames of a video via simple feature matching. (e) Multidimensional scaling of latent codes (via 2D Principal Component Analysis) allows for "at-a-glance" interactive video exploration; one can summarize visual modes and discover repeated frames that look similar but are temporally distant. (f) We average the latent codes of all the frames in a video, and decoding them gives us an average image of a video. The iterative reprojection property of the autoencoder further allows us to sharpen it. We contrast with the average image formed by taking per-pixel mean of the frames (pixels). (g) Manifold projection allow us to align two semantically similar videos and retarget from one to another (here, two baseball games). |
Acknowledgements |