The world is our studio:The onset of mobile phones and cameras have revolutionized the capture scenario. Each one of us carry a powerful camera. There are more cameras at a place than there are humans around. Many public events are captured by different people from various perspectives. The question is: how can we utilize the data from discrete cameras and yet be able to move in the space-time of the event continuously?
The detailed results for each sequence are provided below on this webpage.
Abstract
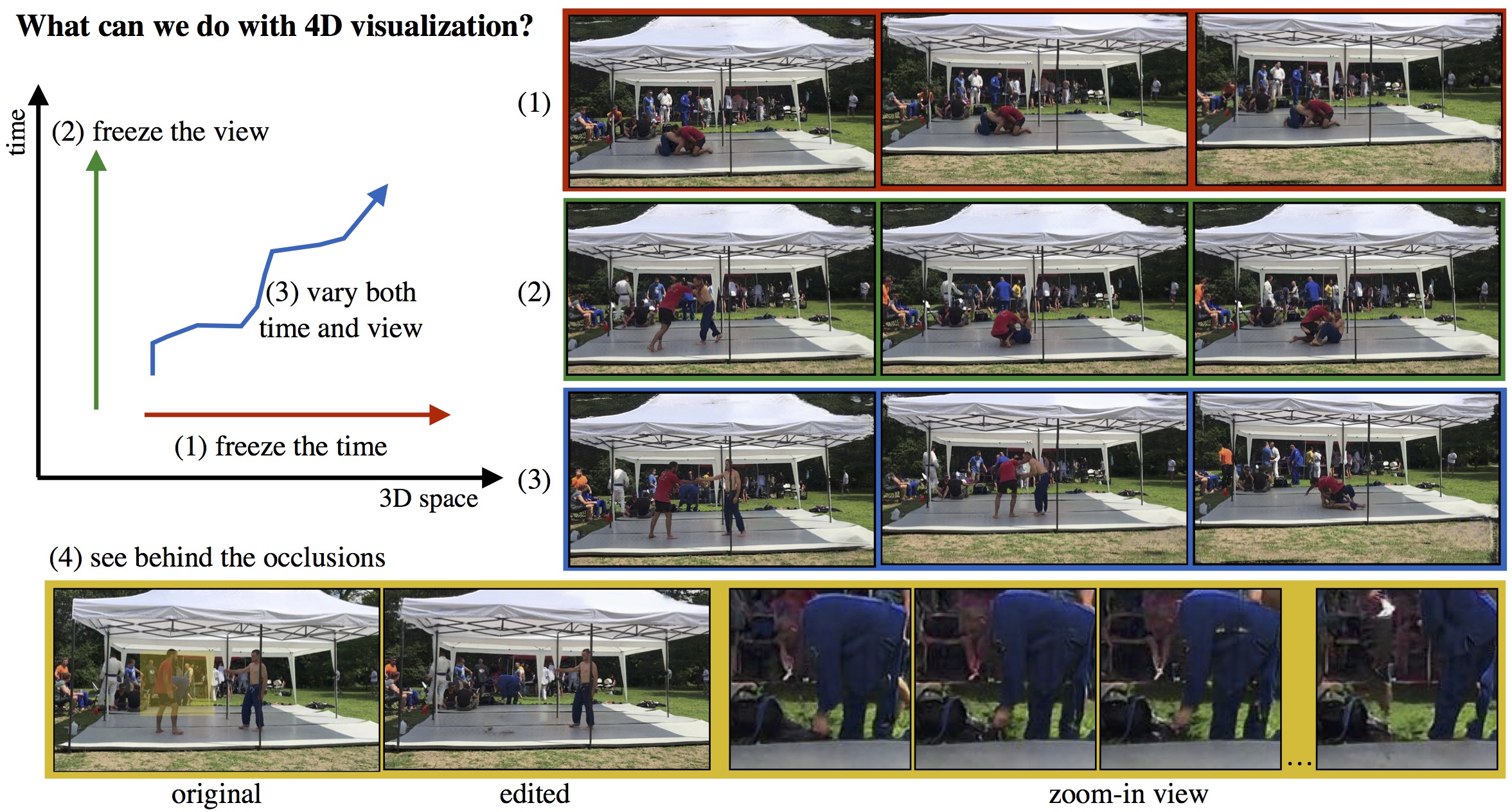
We present a data-driven approach for 4D space-time visualization of dynamic events from videos captured by hand held multiple cameras. Key to our approach is the use of self-supervised neural networks specific to the scene to compose static and dynamic aspects of an event. Though captured from discrete view points, this model enables us to move around the space-time of the event continuously. This model allows us to create virtual cameras that facilitate: (1) freezing the time and exploring views; (2) freezing a view and moving through time; and (3) simultaneously changing both view and time. We can also edit the videos and reveal occluded objects for a given view if it is visible in any of the other views. We validate our approach on challenging in-the-wild events captured using up to 15 mobile cameras.
A. Bansal, M. Vo, Y. Sheikh, D. Ramanan, S. Narasimhan
4D Visualization of Dynamic Events from Unconstrained Multi-View Videos.
In CVPR, 2020.
We contrast the synthesized views with held-out physical camera and nearest neighbors.
Aside: If 4D visualization of dynamic events is posed as a combination of 3D reconstruction of static world and explicit human modeling (assuming human-only events): .
We contrast our approach with a virtual camera created using a combination of COLMAP (Schonberger et al., 2016) for 3D reconstruction from multi-view videos and using human modeling in multi-views from Vo et al., 2020.
Flowing Dress and Open Hair
We thank Melanie Brkovich for the performance in this sequence. We also thank Frank Caloiero and Amy Grove for the help in capture.
Inserting a virtual camera between two physical cameras.
Freezing time and exploring views. As we move the camera, we can see the part of the building which was otherwise occluded.
Aside: If 4D visualization of dynamic events is posed as a combination of 3D reconstruction of static world and explicit human modeling (assuming human-only events): .
We create a virtual camera using COLMAP (Schonberger et al., 2016) for 3D reconstruction from multi-view videos and using human modeling in multi-views from Vo et al., 2020.
Many People and Unchoreographed Sequence
We thank Nica Ross and JiuJitsu School (Pittsburgh) for this sequence.
Inserting a virtual camera between two physical cameras.
Note: Explicit human modeling on this sequence is not easy.
Seeing behind the occlusions.
Challenging Illumination and Self-Occlusion
We thank Sam Caloiero, Sofia Caloiero, Zachary Brkovich, and Melanie Brkovich for the performance in this sequence. We also thank Frank Caloiero and Amy Grove for the help in capture.
Inserting a virtual camera between two physical cameras.
Aside: If 4D visualization of dynamic events is posed as a combination of 3D reconstruction of static world and explicit human modeling (assuming human-only events): .
We create a virtual camera using COLMAP (Schonberger et al., 2016) for 3D reconstruction from multi-view videos and using human modeling in multi-views from Vo et al., 2020.
We thank Yulia Zhukoff (Pittsburgh Tango Connection) for the performance in this sequence. We also thank Heather Kelley and Jessica Gerdel for the help in capture.
Creating many virtual cameras.
Note: Explicit human modeling on this sequence is not easy.
Acknowledgements
We thank Qualcomm Innovation Fellowship for supporting this work. We are extremely grateful to Bojan Vrcelj for helping us shape the project. We thank Gengshan Yang for the help with his disparity estimation code. We thank Dinesh Reddy for discussion and his help with collecting the data. We are very thankful to our many friends who helped us in collecting the various sequences. We also thank the authors of Colorful Image Colorization for this webpage design.